Blog: Zero Shot Learning In Natural Language Processing
What is Zero-Shot Learning?
If you don’t know something, you can refer it to familiar ones for guessing
Zero-Shot (0S) and Few-Shot Learning is designed to address the robustness at test time. ML/DL algorithms are easily prone to unseen samples since they are developed with datasets which do not cover all possible scenarios in reality. Zero-shot methods generally work by associating observed and non-observed classes through some form of auxiliary information which lead to distinguishable properties of non-observed classes [6].
Some types of auxiliary information:
- Learning with attributes: classes paired with predefined attributes. For example, in image classification of dog, additional attributes include skin color, mark pattern, or size.
- Learning from textual description: classes paired with definitions and free-text natural-language descriptions. This is mainly pursued in natural language processing.
- Class-class similarity: the to-be-identified class (aka premise) and the class (aka label) is set into the hypothesis **that if the premise is a kind of label.
Given the auxiliary information, the 0S setting converts multi-class classifiers into binary classifiers which removes the major challenge of classification, the fixed number of labels. Any change in the predefined class list requires re-finetuning or re-training classifiers. Also, there exists challenges of classification with many classes [7].
The 0S setting maps additional data attributes into high-dimensional features during 1. training stage which could then be referred to during 2. inference stage for unseen labels [1]. Hence, 0S is done in 2 stages:
- Training - knowledge about attributes are captured
- Inference - knowledge is used to categorize instances among a new set of classes without the need of fine-tuning
Zero-Shot Learning in NLP
Speaking of the 0S applications in NLP, 0S has been recently formulated as:
- Embedding approach that Chaudhary discusses using NN architectures (e.g. Fully-Connected, LSTM) to embed text and label (also in text format) separately and concatenate them together (figure below) to perform binary classification to decide if label entails text [2, 3]. Even though the concatenation of text and label embedding is not new, the entailment-like binary classification avoids the challenge of many-class classification. This approach employs the Learning from textual description to provide auxiliary info.
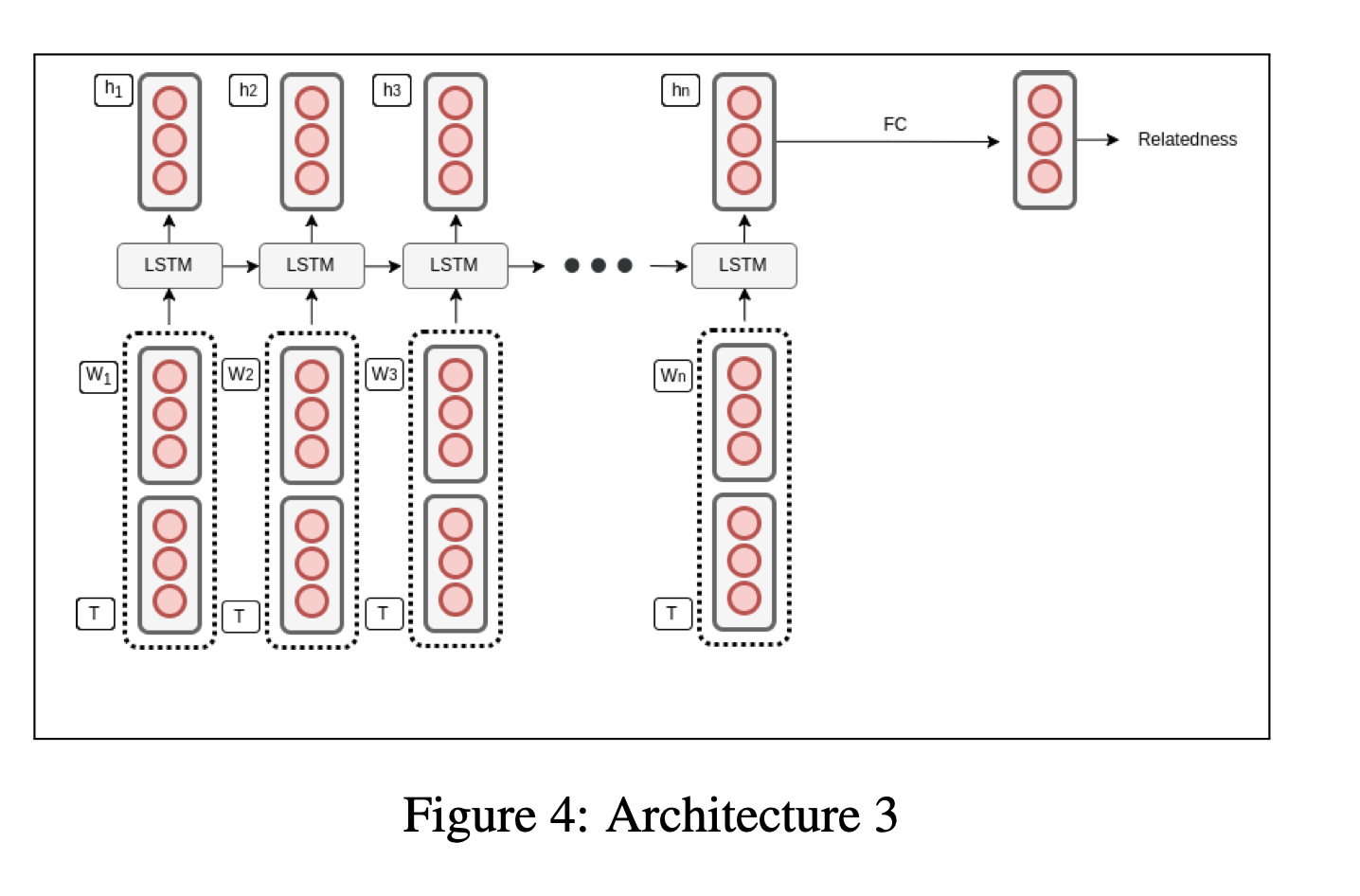
- Transfer Learning that utilizes pretrained Transformer-based language models
(e.g. BART, GPT-3) to read and link context of text and labels for data attributes. Two good examples are:
-
GPT3 by OpenAI is pretrained with a broad set of skills. Hence, instead of fine-tuning for specific tasks, GPT3 can adapt to new downstream tasks (i.e. English-French translation in the figure below) in the zero/few-shot settings by treating task description as textual description.
Unlike the above Embedding approach concatenating two separate embeddings, GPT-3 concatenates text, task description , and few complete examples (if in few-shot settings) into a single text sample which is then embedded for prediction. The text concatenation for a single embedding step is the key direction pursued in NLP.
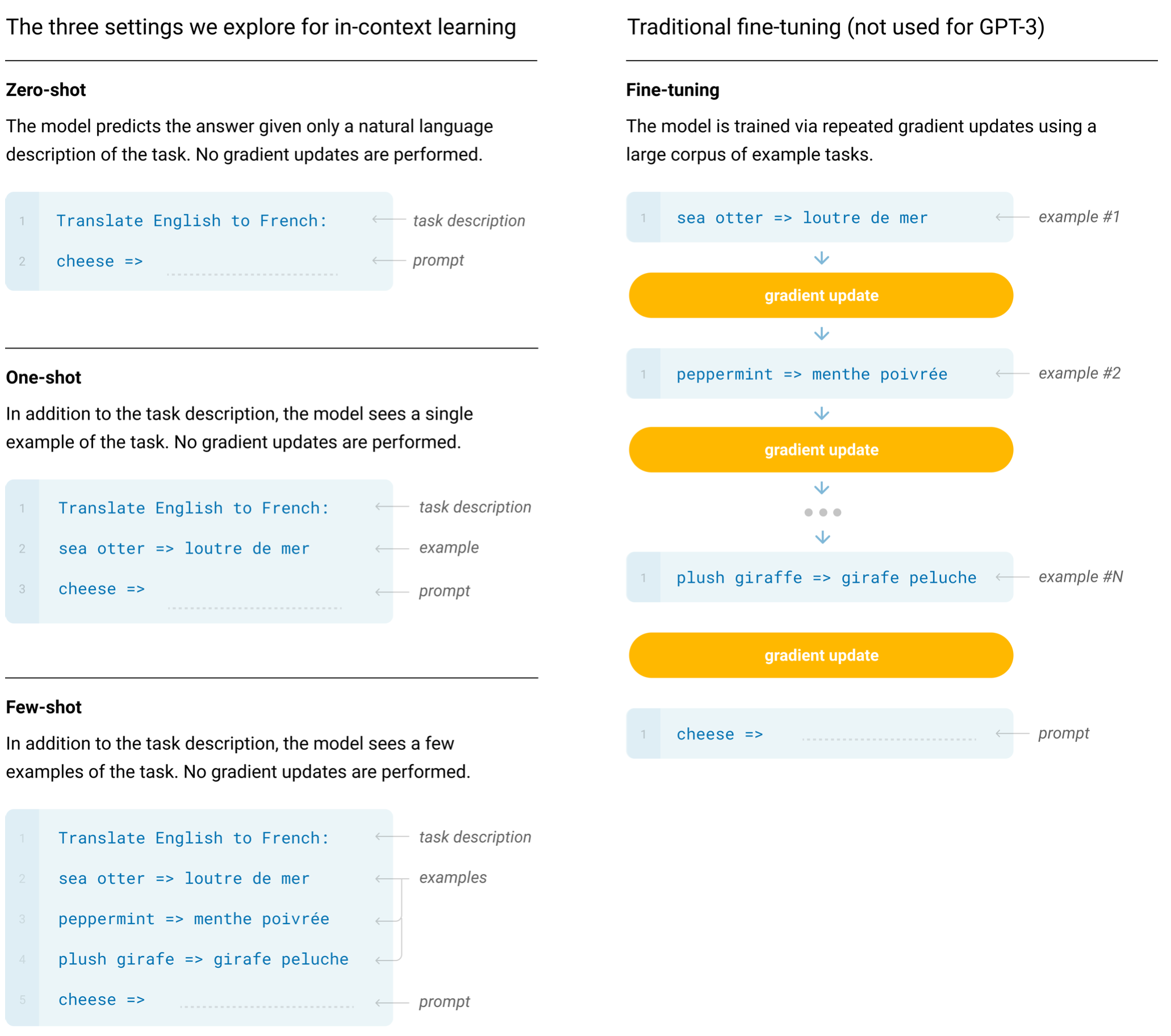
-
Natural-Language-Inference-based for Text Classification by Yin et al. takes the concatenation of text and label (viewed as class-class similarity) as input and performs the entailment-like text classification.
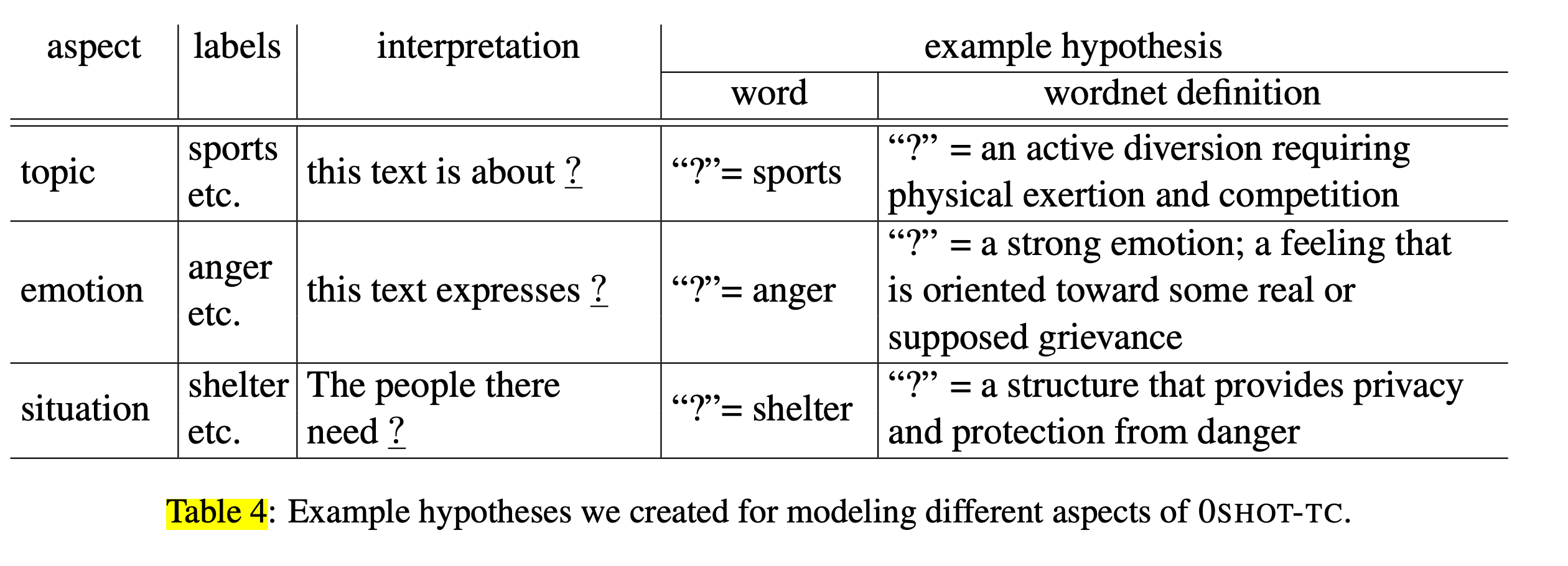
Look at the figure above, to follow class-class similarity, labels are converted into hypothesis format such as “this text is about ?”. The ? is the additional class (e.g. sport), text is any text to be classified (e.g.. World Cup 2018 was organized in Russia). —
-
There are many other zero-shot approaches than what I have introduced above. Despite the zero-shot learning addresses the data unavailability of many classes scenario, the zero-shot setting in inference leads to high latency since there will be 100 complete binary predictions (i.e. feed-forwards) for 100 classes. Regardless, zero-shot is actively researched in both Computer Vision and Natural Language Processing.
References
[1] - Zero-Shot Learning: Can you classify an object without seeing it before?
[2] - Zero Shot Learning for Text Classification
[3] - Train Once, Test Anywhere: Zero-Shot Learning for Text Classification
[4] - Language Models are Few-Shot Learners
[5] - Benchmarking Zero-shot Text Classification: Datasets, Evaluation and Entailment Approach
[6] - Zero-Shot Learning
[7] - Classification with many classes: challenges and pluses
[8] - Natural-Language-Inference-based for Text Classification